Building AI Infrastructure for Large Language Models (LLM) and Foundational Models (FM)

Executive Summary
Based on the published information, the current article examines establishing a training infrastructure for LLM/FM.
An Overview of Cloud and Accelerating computing environments for Deep Learning
What is the latest thought process in computing efficient Deep Neural network training?
Azure-Based Cloud Infrastructure for LLM Training
Why does training an LLM model with billions of parameters cost millions of dollars?
Cloud FinOps, cloud Bill of Materials for LLM Infra (A Learning from Meta OPT-750B Model)
The talent capital and Key challenges to look for.
Introduction
Large Language Models and Foundation Models are becoming a mainstream technology and influencing enterprises' IT and AI roadmaps. Despite all the growing speculations and call for precautions and governance, the technology made its way to an accessible one. For many, implementing and integrating LLM base solutions are now equivalent to an intelligent mashup solution. The current article explores the path toward building a massively scalable infrastructure to build foundational models and LLMs’.
LLM and Computing Requirments
LLMs are neural network architecture inspired by the famous research paper ‘Atten Is All You Need’[1]. They are built on top of the vast knowledge curated and accessible over the internet for the last few decades. They are trained on trillions of tokens (approximately equal to a word or character, depending on the language) and billions of parameters. Building such massive and intelligent models requires massive infrastructure. The advent of accelerated computing, such as GPU, TPU, and FGPA, directly contributed to the nuclear explosion in AI. Considering all these facts and accessibility to the pool of intellects and theoretical frameworks, there is a place for Infratscture and IT DevOps. Organizations that invested and made successful in building LLMS and other foundational models had identified the path to ideal infrastructure and effective utilization. Being in the cloud-native world, such a journey was always fueled by the knowledge and expertise from High-Performance Computing (HPC), which workloads scientific organizations running for ages. Free and Open Source Technologies, Open Knowledge, advances in computing, cloud technologies, and a diversified pool of intellectuals are the secret sauce.
Access to GPU and Cloud Alone is not Enough!
It is well known that accelerated computing, such as GPU, TPU, or FPGAs, is not cheap, even if you rely on the cloud. Having access to massive computing power such as Cloud and GPU alone wont help any organization effectively invest in LLM or Foundational models. To unleash the true potential of the hardware, combine it with your methodology and make models that need innovative methodology. This is a well-explored field of study, and it continues to evolve because building massive models with less cost will be the motto for all LLM/Foundation Model creators. We can't ignore the sustainability part of it, too; we should not leverage 25% of California's power to build LLM![5] Data Parallelism, Pipeline Parallelism, Tensor Parallelism, and Expert Parallaism are four major methodologies in this space. I am not venturing into these areas in this article; Lillian and Greg from OpenAI cover this in their blog ‘Techniques for Training Large Neural Networks [2]. Without employing such innovative methodology, the AI Infra will be like using a truck to buy a daily packet of milk from a grocery store.
Well, we finally landed in the Neural Network architecture training methodology. How do we create an infrastructure and monitor it? The training is going to take a week or months. We may need to scale, refactor and monitor the Machine Learning metrics. We identified the massive data sets, the training weights, and the logs to be stored and visualized with Tensorboard. The team of AI experts should effectively collaborate. How do we achieve all of these? This is where the IT DevOps and Cloud Infrastructure team joins hands with LLM/Foundation Models team.
The Infrastructure
The reference infrastructure in this article is based on the Azure Cloud; the same guiding principle can be adopted in other clouds, such as AWS or GCP. The guiding principle for this infrastructure comes from deploying on-premise HPC systems.
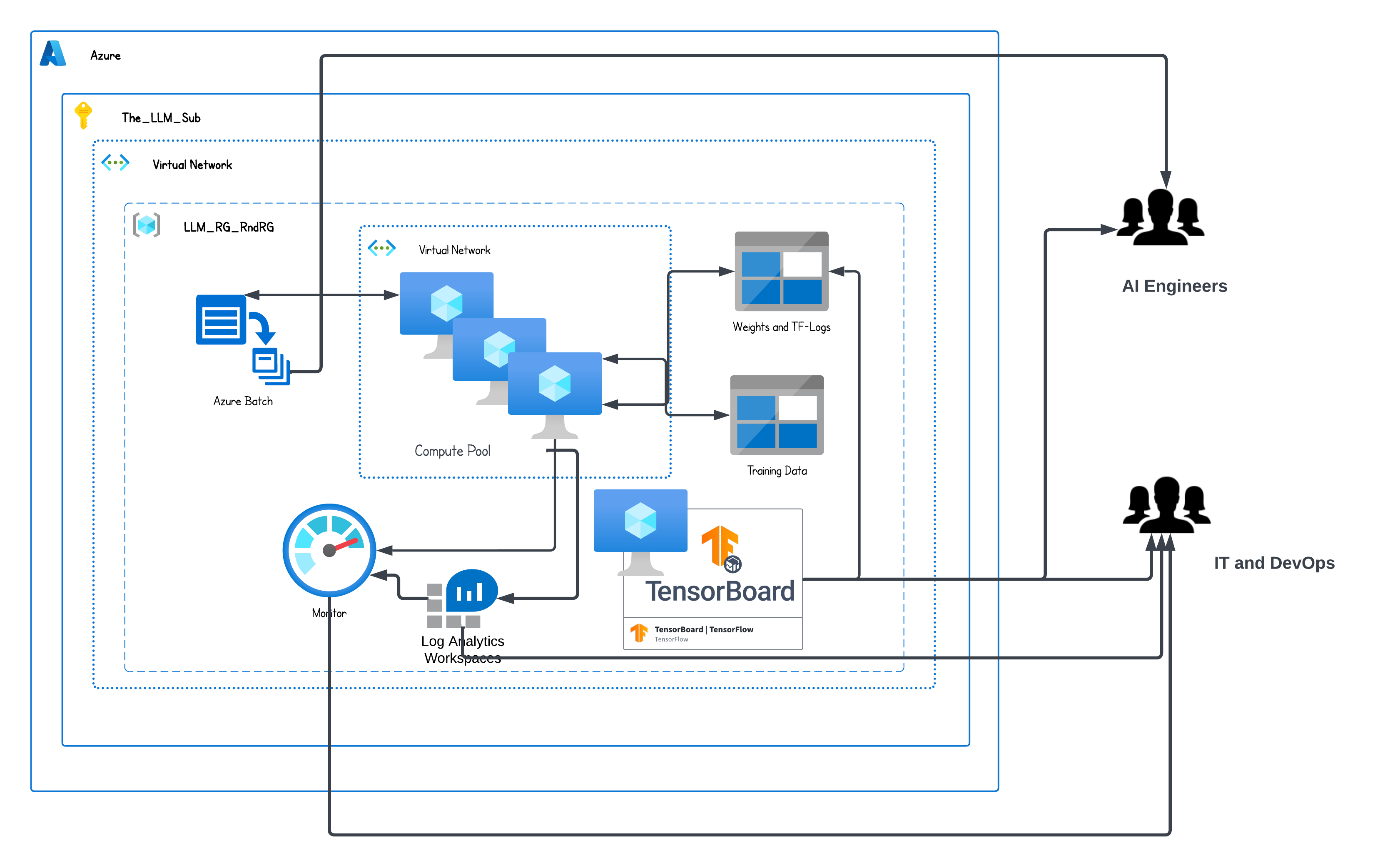
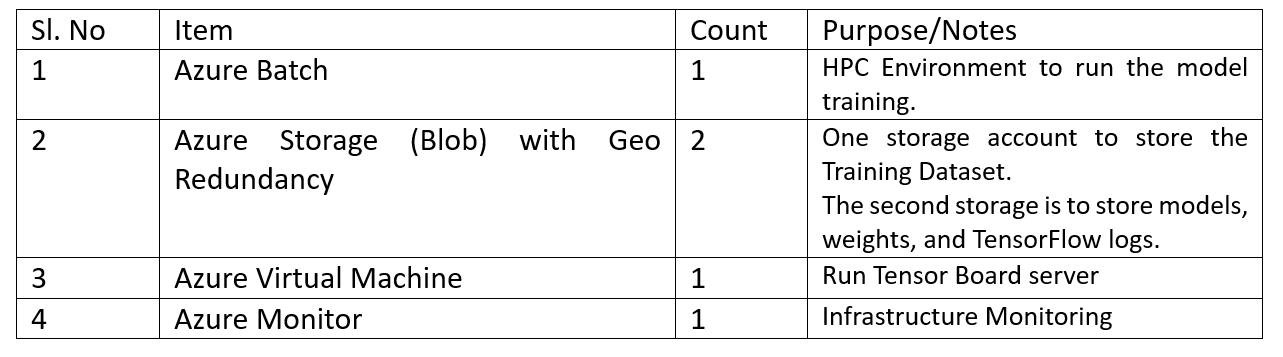
The Azure cloud abstracts the HPC into their service, namely ‘Azure Batch.’ The overall bill of materials for this infrastructure consists of the following components.
Why HPC Infrastructure?
High-performance computing (HPC) is nothing new in the scientific world. From simulations to AI, many use cases are still implemented in HPC environments. The ease of adding new nodes and slicing dicing of infrastructure resources made it a favorite for the scientific computing community. When HPC moved to the cloud, the elasticity of resources became more agile. Managing the compute and effective and proven tool chains to manage jobs like the ‘slurm’ makes it a first-class choice for IT DevOps teams too. While we are experiencing with FM or LLM models adding new GPU nodes to speed up the overall execution is easy. All the major cloud vendors offer NVIDIA GPU with Infiband for high throughput and low latency. This ensures seamless data and model transfer between GPU nodes and efficient compute capacity utilization.
Cloud FinOps for LLM/FM
The discipline of ClodFinOps deals with show back and chargeback of IT Infarstcrure cost and spending. Based on the infra architecture above, we are trying to portray the cost of running an LLM training in Azure with the necessary security elements. After reverse-reading Meta’s OPT-175B model report and paper, the monthly cost for the model training cloud has ~ $2,566,422.22 per month. This cost is based on the published standard pricing. The OPT-17B model was trained on approx One hundred twenty-four nodes for ~2.5 months. Without any discounts and minus applicable taxes, the cost could have been $6,416,105.55. Based on the unit pricing, enterprise support models, and the strategic relationship with Meta and Microsoft, there might have been a flat 10 to 30% of this price (assumption). The numbers match the notes provided in the model logbook published by Meta [4]. This is a huge price for one of the initial publically accessible models Meta created. The models are available for researchers and the community to build non-commercial solutions. Spending approximately six million on such an initiative should have proven ROI in the long run.
The Talent Capital
Talent acquisition and retention are equally important along with the infrastructure. The original research paper shows that 19 brilliant minds collaborated in the 177-B model. Considering the SR and IT Support, it could have been a team of 25 direct staff members. Considering the growing impact of revealing source code and papers and the hunt for LLM talent, retention will be the focus while engaging such a vibrant team in impactful work.
Key Engineering Lessons in LLM Infra and Model Operations
The challenges will be known for most Engineering leaders working in Scientific experiments and AI Infra. Some of the team's low-level issues are node draining and GPU driver issues in the nodes. Timely detection and remediation are essential to avoid resource waste. In a hundred-node set-up, five nodes going out and being in a dead state due to driver issues may waste ~$3,000 * 10 = 30,000 wastage for an hour (the node is live, but the training is not running in the node). Empowering the DevOps/ITOps team with the proper infrastructure tools is critical to success and ensuring Engineering Leaders effectively utilize the Cloud Budget and resources. One of the interesting observations from the Meta OPT-750B[3] model is the Data Scientist/AI Engineer Collaboration aspects. There was a point when two developers' Python environments and library versions were not matched (classic Data Science case of ‘it works in my conda environment’). Shared spaces with shared environment spec and leveraging the scientific computing power containers such as Singularity is an added advantage. It is worth investing time to educate some of the toolchain aspects to the data Science/Engineers to omit the apparent challenges. As a practitioner, I still believe in the power of HPC and the Singularity container environment.
Conclusion
Building LLM/FM requires significant investments in Deep Learning, Data Parallel Computing, and Accelerated computing. At the same time, the ultimate power to execute these intellectual marvels to gain momentum and business value lies the effective infrastructure design. Efficient utilization of resources, identifying and mitigating the challenges while the best minds innovating the next human-like mind is an art and science learned and practiced from HPC Infrastructure, Cloud, and IT Operations. The perfect blend of design choices in Clououf Infra provider, establishing a DevOps and IT relation, negotiating the IT unit price, and maintaining healthy Cloud FinOps practice plays an important role.
Notes
The architecture and approximate cloud cost estimations are based on the logs Meta published to the open domain. There is a chance of some assumption-based errors in some of the numbers. Hence it is advised to consider some of the numbers as indicative only. None of the opinions expressed in this article does endorse the views of my employers or customers.
References
[1] Attention Is All You Need - https://arxiv.org/abs/1706.03762
[2] Techniques for Training Large Neural Networks - https://openai.com/research/techniques-for-training-large-neural-networks
[3]Democratizing access to large-scale language models with OPT-175B, https://ai.facebook.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/
[4] https://github.com/facebookresearch/metaseq
[5] Rant adopted from Noam Chomsky's comments on LLM